引言
前一篇文章将基本的网络同步例子制作出来,虽然还有很多问题,但是我们已经在网络问题很简易的摆放在我们面前,不需要经过服务器,就可以简单的模拟经常出现的网络延迟现象,那对于之前演示的问题,如何解决呢?今天就解决第一步,发包的问题。如果能够节省发包量?
状态更新
因为每个客户端都有自己的逻辑运算,所以我们很明显的就可以想到,只需要在状态更新时发送即可,对于一般的游戏这个方案都可以解决,比如我们修改速度的时候,游戏点击目标点的时候,这些时间点发送即可,对于之前的例子,我们只需要做如下判断就可以节省大量的通讯量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 获取输入
// 在通过键盘获取输入更新最新速度前
var lastVelocity:Vector2 = localPlayer.velocity.clone();
var lastAcceleration:Vector2 = localPlayer.acceleration.clone();
if (lastVelocity.x != localPlayer.velocity.x ||
lastVelocity.y != localPlayer.velocity.y ||
lastAcceleration.x != localPlayer.acceleration.x ||
lastAcceleration.y != localPlayer.acceleration.y) {
update = true;
}
if (update) {
var p:PlayerStatePack = new PlayerStatePack();
p.velocity = localPlayer.velocity.clone();
p.position = localPlayer.position.clone();
p.acceleration = localPlayer.acceleration.clone();
p.time = getTimer();
client.send(p);
}
|
Network1.swf
我们再看现在的demo,通讯量明显下来了,而且网络场景走得也不差。
当然,这个方案也是有其局限性的,比如如果加速度存在的话,那速度每时每刻是不一样的,所以发包频率还是非常频繁,还有一种更极端的情况,如果你加入了物理引擎,或者使用了自治智能体,此时连加速度都每时每刻在变化的,有没什么更好的方式来优化通讯量呢?下面引出下一个优化方案,航位预测法(DeadReckoning)。
航位预测法(DeadReckoning)
这种算法比较的主要是位置,而非上面的速度以及加速度,所以从通用性上来说,会好很多。具体的细节为,当本地个体与记录的上次本地个体(即其他网络场景看到的自己)的位置超过某个阈值,则发送更新状态包,当此阈值越小,则发送包频率越快,此阈值越大,则发送包频率越慢,也越节省。
基本的原理可参考如下图(从网络获取)
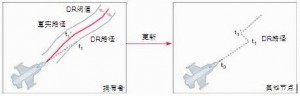
基本实现代码如下
1
2
3
4
5
6
7
8
9
10
11
12
|
// dr位置
var drPosition:Vector2 = new Vector2();
if (lastState) {
var e:Number = (getTimer() - lastStateTime) / 1000;
// s = v0t + 0.5 * a * t^2;
drPosition.addVectors(lastState.position, lastState.velocity.clone().multiply(e).add(lastState.acceleration.clone().divide(2).multiply(e * e)));
}
// 阈值
var threshold:Number = 5 * 5;
if (localPlayer.position.distSQ(drPosition) > threshold) {
update = true;
}
|
代码很简单,就是牛顿力学的内容,位移,加速度,速度的公式,然后算出dr位置(即网络位置),如果超过阀值,则发送更新包,另外记录上次发送状态(为了计算下一次dr位置)。
演示如下
Network2.swf
应用
在游戏中,状态更新及航位预测可混合使用,如在键盘更新时,即可将状态更新包发出,而非一定要等到位置偏移超过一定值,这样网络网络场景看到的会更即时些。本章将发包的问题解决了,但是你可以在演示中看出,当网络延迟波动较大时,网络场景的物体拖拉很生硬,因为我们直接设置了网络场景的位置到了当前位置,下一部分介绍如何用插值平滑将网络延迟做进一步的遮掩。
参考文献